深入探索概率论:从收敛性到核心概念
几乎必然收敛 (Almost Sure Convergence):最强的收敛形式
几乎必然收敛 指的是,随机变量序列 $X_n$ 在概率空间中"几乎所有"的样本路径上都收敛于 $X$。直观地说,就是有 100% 的概率(Probability = 1),当 $n$ 足够大时,$X_n$ 会无限接近 $X$,并永远保持在 $X$ 附近。
对于抛硬币的例子,这就是强大数定律 (Strong Law of Large Numbers):样本中正面的比例几乎必然收敛到真实概率 0.5。这是最强的收敛形式,它也意味着其他所有类型的收敛。
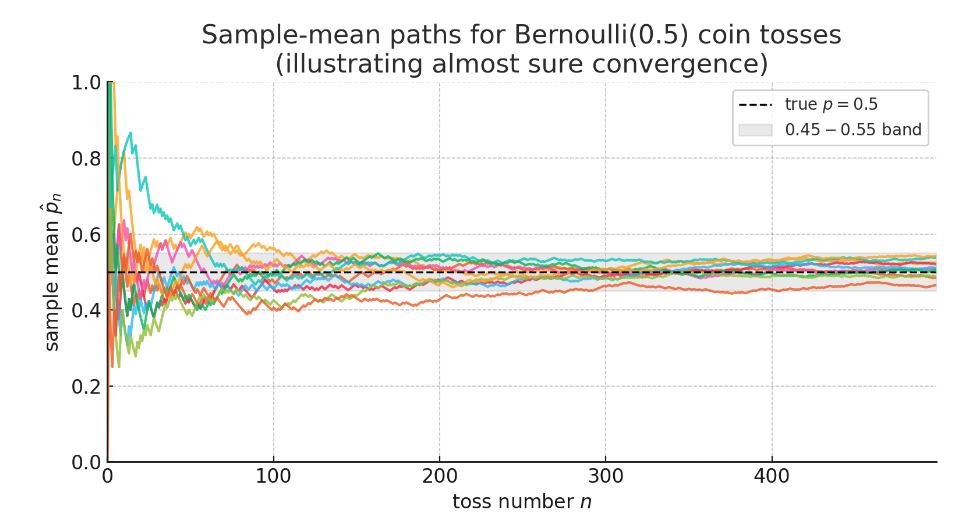
上图(10条彩色曲线)展示了几乎必然收敛:
每条曲线代表一次完整的实验——不断抛掷一枚均匀硬币,其中 x 轴是抛掷次数 $n$,y 轴是前 $n$ 次抛掷中正面的比例 $\hat{p}_n$。
- 黑色虚线: 真实概率 $p=0.5$
- 灰色带: 0.45–0.55 的区间,代表直观上的"稳定"范围
关键观察点:
初期,波动非常剧烈(有些曲线甚至触及 0 或 1)。
随着 $n$ 的增加,所有路径都逐渐稳定下来,并永久地停留在灰色带内。
它们再也不会偏离 0.5 太远——这就是强大数定律:
$$\mathbb{P}\left(\lim_{n\to\infty}\hat{p}_n = 0.5\right) = 1$$
如果我们能画出无穷多条路径,几乎每一条都会这样表现。只有那些概率为 0 的路径可能会永远振荡——但你基本上永远观测不到它们。
依概率收敛 (Convergence in Probability):实用的标准
依概率收敛 指的是,当 $n \to \infty$ 时,$X_n$ 与 $X$ 的差异大于任意一个微小阈值 $\varepsilon$ 的概率趋近于零:$\Pr(|X_n - X| > \varepsilon) \to 0$。
这比几乎必然收敛要弱。虽然对于很大的 $n$ 来说,$X_n$ 通常非常接近 $X$,但偶尔的巨大偏离仍然是可能发生的。弱大数定律 (Weak Law of Large Numbers) 证明了样本均值依概率收敛于其期望值。
一个经典反例: 考虑一个随机变量 $X_n$,它以 $1/n$ 的概率取值为 1,否则取值为 0。那么 $\Pr(X_n = 1) = 1/n \to 0$,所以 $X_n \xrightarrow{p} 0$(依概率收敛于 0)。然而,由于级数 $\sum_n 1/n$ 是发散的,几乎必然会存在无穷多个时刻使得 $X_n = 1$,这意味着样本路径实际上并没有收敛到 0。这表明依概率收敛不保证几乎必然收敛。

上图中的黄色尖峰代表随机变量 $X_n$——它大部分时间取值为 0,但偶尔会(以 $1/n$ 的概率)跳到 1。红色曲线显示了这个概率 $1/n$ 是如何随 $n$ 减小的。
随着 $n$ 的增加,取到 1 的概率越来越小,满足: $$\Pr(|X_n-0|>\tfrac{1}{2}) = \Pr(X_n=1) = \tfrac{1}{n} \longrightarrow 0$$ 这证实了依概率收敛:$X_n\xrightarrow{p}0$
然而,观察单个路径会发现:尖峰变得越来越稀疏,但永远不会完全消失——无论 $n$ 多大,1 仍然会偶尔出现,因此样本路径并没有真正收敛到 0。
这清晰地展示了:依概率收敛 ≠ 几乎必然收敛。
依分布收敛 (Convergence in Distribution):最弱的收敛形式
依分布收敛 指的是 $X_n$ 的累积分布函数 (CDF) 收敛于 $X$ 的累积分布函数。通俗地说,就是随机变量的概率分布形状逐渐变得相似,但我们不关心单次实现的值是否接近。
这是最弱的收敛形式。中心极限定理 (Central Limit Theorem) 就是一个最好的例子:无论原始分布是什么(只要方差有限且观测是独立同分布的),标准化后的样本均值都会依分布收敛于标准正态分布。
核心关系: 几乎必然收敛 $\implies$ 依概率收敛 $\implies$ 依分布收敛。反向关系通常不成立,正如我们的反例所示。
当矩的收敛失效时
这里有一个令人惊讶的事实:依概率收敛并不保证方差也收敛。思考下面这个反例:
定义 $X_n$:以 $1/n$ 的概率,$X_n = \sqrt{n}$;否则 $X_n = 0$。
- 期望: $\mathbb{E}[X_n] = \sqrt{n} \cdot \frac{1}{n} + 0 \cdot (1-\frac{1}{n}) = \frac{1}{\sqrt{n}} \to 0$
- 方差: 由于 $X_n$ 要么是 0 要么是 $\sqrt{n}$,我们有 $\mathbb{E}[X_n^2] = n \cdot \frac{1}{n} = 1$。因此 $\operatorname{Var}(X_n) = \mathbb{E}[X_n^2] - (\mathbb{E}[X_n])^2 = 1 - \frac{1}{n} \to 1$
这个 $X_n$ 依概率收敛于 0(因为 $\Pr(X_n \neq 0) = 1/n \to 0$),但它的方差却收敛于 1,而不是 0!原因在于:尽管极端值出现的频率越来越低,但其数值却越来越大,从而维持了它们对整体方差的贡献。
这个例子揭示了,在收敛过程中,随机变量的不同方面(如期望和方差)可能有截然不同的行为,这要求我们仔细分析收敛的具体对象。
第二部分:塑造我们世界的极限定理
中心极限定理:为何标准化至关重要
场景: 想象一下,你投掷很多个骰子并记录它们的点数之和。掷 1 个骰子时,结果是均匀分布(1-6)。掷 2 个骰子时,和的分布变成三角形(2-12,中心在 7)。那么掷 10 个骰子呢?直觉告诉我们,这个和的分布会趋近于一条"钟形曲线"。
这个直觉被中心极限定理 (CLT) 形式化了:大量独立同分布的随机变量之和(或均值),在经过适当的标准化之后,会依分布收敛于一个正态分布——无论原始分布的形状如何。
为何需要标准化? 如果不进行标准化,点数之和 $S_n = X_1 + \cdots + X_n$ 的均值为 $n\mu$,标准差为 $\sqrt{n}\sigma$,它们会无限增长。为了观察到一个有意义的极限分布,我们需要通过减去均值 $n\mu$ 来中心化,再通过除以标准差 $\sqrt{n}\sigma$ 来缩放:
$$Z_n = \frac{S_n - n\mu}{\sigma\sqrt{n}} = \frac{\overline{X}_n - \mu}{\sigma/\sqrt{n}}$$
中心极限定理指出,当 $n \to \infty$ 时,$Z_n$ 依分布收敛于标准正态分布 $N(0,1)$。
实际意义: 对于较大的 $n$,$\Pr(|\overline{X}_n - \mu| < 3\sigma/\sqrt{n}) \approx 0.997$。这量化了样本均值的波动范围:它以 $O(1/\sqrt{n})$ 的速度缩减,而常数 "3" 对应于正态分布的 99.7% 置信区间。
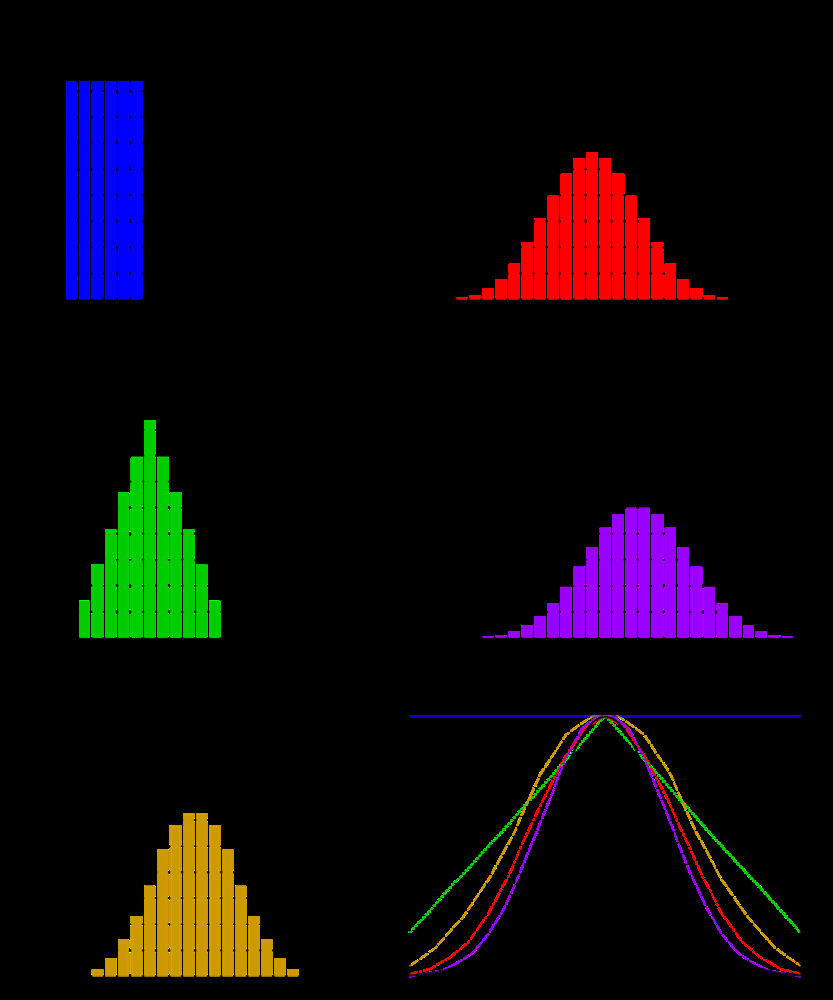
上图展示了骰子点数之和如何逐渐逼近正态分布。左上:1个骰子(均匀分布)。右上:2个骰子(三角形分布)。左下:3个骰子(更集中)。右下:将1、2、3、4个骰子点数和的平滑曲线与标准正态曲线(黑色)叠加。随着骰子数量增加,和的分布越来越接近正态分布。
例子: 假设我们测量一批机器零件的误差 $X$,其分布未知,但已知均值 $\mu=0$,标准差 $\sigma=2$ 毫米。对于 $n=36$ 个零件,其平均误差 $\overline{X}{36}$ 满足 $\sqrt{36}(\overline{X}{36}-0)/2 \approx N(0,1)$。因此,$\Pr(|\overline{X}_{36}| < 1) \approx \Pr(|Z| < 3) \approx 0.997$。这意味着平均误差落在 ±1 毫米内的概率约为 99.7%。
从二项分布到泊松分布:稀有事件定律
场景: 一个网站有大量用户 $n$,每个用户在某一天执行某个操作(如登录)的概率很小,为 $p = \lambda/n$。那么总共有多少用户会执行这个操作?
当 $n$ 很大,$p$ 很小,而它们的乘积 $np = \lambda$ 保持在一个适中的值时,二项分布可以用泊松分布来近似。这就是稀有事件定律,在通信、排队论和可靠性工程中是基础性的理论。
数学推导: 设 $X_n \sim \text{Binomial}(n, \lambda/n)$。我们有 $\mathbb{E}[X_n] = \lambda$ 且 $\operatorname{Var}(X_n) \approx \lambda$(因为当 $p$ 很小时 $(1-p) \approx 1$)。
其概率质量函数为: $$\Pr(X_n = k) = \binom{n}{k} p^k (1-p)^{n-k} = \frac{n!}{k!(n-k)!}\left(\frac{\lambda}{n}\right)^k \left(1-\frac{\lambda}{n}\right)^{n-k}$$
当 $n \to \infty$ 且 $k$ 固定时:
- $\frac{n!}{(n-k)!} = n(n-1)\cdots(n-k+1) \approx n^k$
- 因此 $\binom{n}{k} \left(\frac{\lambda}{n}\right)^k \approx \frac{n^k}{k!} \left(\frac{\lambda}{n}\right)^k = \frac{\lambda^k}{k!}$
- $\left(1-\frac{\lambda}{n}\right)^{n-k} \approx \left(1-\frac{\lambda}{n}\right)^{n} \to e^{-\lambda}$ (使用标准极限)
将它们合并:$\Pr(X_n = k) \to e^{-\lambda}\frac{\lambda^k}{k!}$,这正是泊松分布 Poisson$(\lambda)$ 的概率质量函数。
经验法则: 如果 $n \geq 100$ 且 $np \leq 10$,用泊松分布近似二项分布通常相当准确。
第三部分:量化不确定性的实用工具箱
当我们对一个随机变量的分布知之甚少时,概率不等式为我们估算其尾部概率提供了至关重要的边界。不同的不等式需要不同的假设,并提供不同紧密度的界。
马尔可夫不等式 (Markov's Inequality):最普适的界
对于任意非负随机变量 $X \geq 0$: $$\Pr(X \geq a) \leq \frac{\mathbb{E}[X]}{a}$$
优点: 仅需知道均值。缺点: 界限通常非常宽松。
例子: 如果一个模型的误差 $E \geq 0$ 的期望 $\mathbb{E}[E] = 5$,那么 $\Pr(E \geq 50) \leq 5/50 = 0.1$。这是一个上界——真实概率可能远小于此。
切比雪夫不等式 (Chebyshev's Inequality):利用方差信息
对于任意方差有限的随机变量: $$\Pr(|X - \mathbb{E}[X]| \geq \varepsilon) \leq \frac{\operatorname{Var}(X)}{\varepsilon^2}$$
优点: 不需要变量非负或有界,当方差已知时,通常比马尔可夫不等式给出更紧的界。
例子: 如果模型误差 $E$ 的期望 $\mathbb{E}[E] = 0$,方差 $\operatorname{Var}(E) = 25$,那么 $\Pr(|E| \geq 10) \leq 25/10^2 = 0.25$。
霍夫丁不等式 (Hoeffding's Inequality):有界变量的力量
对于 $n$ 个独立的有界随机变量 $X_1, \ldots, X_n$,且 $X_i \in [0,1]$: $$\Pr(|\overline{X}_n - \mathbb{E}[\overline{X}_n]| \geq \varepsilon) \leq 2\exp(-2n\varepsilon^2)$$
这个不等式提供了指数级集中的性质,使其在 $n$ 很大时极为强大。
示例对比: 假设我们希望样本均值与真实均值的偏差超过 $\varepsilon = 0.1$ 的概率低于 5%:
- 霍夫丁不等式: 解 $2e^{-2n(0.1)^2} < 0.05$,得到 $n > 184$(约需要 185 个样本)。
- 切比雪夫不等式: 假设最坏情况下的方差为 0.25(对于[0,1]区间),解 $\frac{0.25}{n(0.1)^2} < 0.05$,得到 $n > 500$。
随着 $n$ 的增加,霍夫丁不等式的指数优势变得非常显著:它提供了按 $e^{-cn}$ 衰减的界,而切比雪夫不等式是按 $1/n$ 衰减。
如何选择合适的不等式?
- 马尔可夫: 当你只知道均值且变量非负时使用。界限很宽松,但聊胜于无。
- 切比雪夫: 当你知道方差但不能保证变量有界时使用。为任何方差有限的分布提供了通用的尾部概率控制。
- 霍夫丁: 当变量有界且独立时使用。给出指数级集中的界,对大样本量尤其有效。在机器学习的泛化分析和 A/B 测试中至关重要。
第四部分:基础分布的核心性质
无记忆性:等待越久,机会越大吗?
场景: 你在公交站等了 30 分钟。有人安慰你说:"别担心,你都等了这么久了,车肯定快来了!" 这种安慰有数学依据吗?
如果公交车的到站时间遵循指数分布,那么这种直觉是错误的。指数分布具有无记忆性 (Memoryless Property):过去的等待时长不影响未来的等待时间。
数学定义: 对于任意 $s, t \geq 0$: $$\Pr(X > s+t \mid X > s) = \Pr(X > t)$$
在你已经等待了 $s$ 单位时间的前提下,还需要再等待 $t$ 单位时间的概率,等于一开始就需要等待 $t$ 单位时间的概率。
指数分布的验证: 设累积分布函数 $F(x) = 1 - e^{-\lambda x}$,则生存函数为 $\Pr(X>x) = e^{-\lambda x}$: $$\Pr(X > s+t \mid X > s) = \frac{\Pr(X > s+t)}{\Pr(X > s)} = \frac{e^{-\lambda(s+t)}}{e^{-\lambda s}} = e^{-\lambda t} = \Pr(X > t)$$
启示:
- 在服务时间呈指数分布的排队系统中,系统对你已等待多久没有"记忆"。
- 这极大地简化了马尔可夫过程的分析。
- 然而,大多数真实系统确实存在老化效应,因此指数模型是一种近似。
使用标准正态分布
场景: 统计学考试经常问:"已知 $X \sim N(\mu, \sigma^2)$,求 $\Pr(X \leq a)$。" 由于正态分布没有封闭形式的累积分布函数,我们依赖于标准化和查表。
标准化流程:
- 转换为标准正态分布:$Z = \frac{X - \mu}{\sigma}$,其中 $Z \sim N(0,1)$。
- 重写概率:$\Pr(X \leq a) = \Pr\left(Z \leq \frac{a - \mu}{\sigma}\right)$。
- 使用标准正态分布表(或计算器)查找 $\Phi(z) = \Pr(Z \leq z)$。
关键技巧:
- 处理负值: 利用对称性,$\Pr(Z \leq -z) = \Pr(Z \geq z) = 1 - \Pr(Z \leq z)$。
- 计算区间概率: $\Pr(a < X < b) = \Pr(X \leq b) - \Pr(X \leq a)$。
- 记住 68-95-99.7 法则: 分别约有 68%、95% 和 99.7% 的数据落在距离均值 1、2、3 个标准差的范围内。
第五部分:线性代数的支柱作用
许多高级概率概念,尤其是在多变量分析或机器学习应用(如主成分分析 PCA)中,都严重依赖线性代数。以下是对关键概念的直观回顾。
通过几何直觉理解矩阵性质
场景: 想象一个线性变换 $A$ 作用于一个二维平面,将一个正方形拉伸成一个矩形。哪些性质可以描述这个变换?
秩 (Rank): 线性无关的行/列数,衡量变换后输出空间的维度。秩 $r < n$ 意味着某些维度被压缩了(存在非零向量 $v$ 使得 $Av=0$)。
行列式 (Determinant): 衡量体积的缩放比例,其符号表示方向是否被翻转。$\det(A) = 0$ 意味着变换将空间压缩到零体积(即秩亏损)。
特征值 (Eigenvalues) 与特征向量 (Eigenvectors): 在变换中只进行缩放的特殊方向:$Av = \lambda v$。特征值 $\lambda$ 是缩放因子;特征向量 $v$ 是不变的方向。
迹 (Trace): 矩阵对角线元素之和,它也等于所有特征值之和:$\operatorname{tr}(A) = \lambda_1 + \lambda_2 + \cdots + \lambda_n$。
核心关系
对于任意 $n \times n$ 矩阵 $A$,其特征值为 $\lambda_1, \ldots, \lambda_n$:
- $\operatorname{tr}(A) = \lambda_1 + \lambda_2 + \cdots + \lambda_n$ (特征值之和)
- $\det(A) = \lambda_1 \cdot \lambda_2 \cdots \lambda_n$ (特征值之积)
- 秩 = 非零特征值的数量
这些关系揭示了深刻的联系:存在零特征值 ⟺ 行列式为零 ⟺ 秩亏损 ⟺ 某些方向被压缩为零。
几何直观: 对于对角矩阵 $A = \begin{pmatrix}3 & 0\0 & 2\end{pmatrix}$,x 轴被拉伸 3 倍,y 轴被拉伸 2 倍。在这里,坐标轴就是特征向量,对应的特征值是 3 和 2。我们有 $\operatorname{tr}(A) = 5$,$\det(A) = 6$,秩 = 2。
结论
这趟概率论之旅揭示了,像"收敛"这样看似简单的概念,背后隐藏着具有深远实际影响的微妙区别。理解中心极限定理的适用条件、选择恰当的概率不等式、认识到无记忆性的影响,这些都是现代数据科学和机器学习从业者的必备技能。
这些概念——从收敛模式到极限定理,再到实用的概率边界——相互关联,共同构成了我们精确推理不确定性的数学基石。无论你是在分析 A/B 测试结果、构建机器学习模型,还是设计科学实验,这些工具都能提供严谨的框架,帮助你将数据转化为可靠的洞见。
随着我们处理日益复杂的数据和模型,回归这些基本原理,能确保我们的结论是建立在坚实的数学基础之上,而不是依赖于那些直观但可能误导人的经验法则。