统计推断基础:从数据到决策
典型的统计分析遵循以下步骤:
- 定义问题: 我们想要揭示的具体真相是什么?(例如,"新药的真实有效率是多少?")
- 规划数据收集: 我们将如何收集相关数据?(例如,设计临床试验或调查。)
- 分析数据: 使用统计模型分析数据并做出推断。
- 评估不确定性: 量化我们推断的可靠程度。
"模型"的概念在这里至关重要。模型是关于产生我们数据的随机过程的一组假设。如果我们模型的假设有缺陷,我们的结论就会不可靠。正如一位教授恰当地说道:"如果我收集班上所有学生的鞋码来预测他们的 GPA,这几乎是不可能的。" 这突出了一个基本规则:数据必须与问题相关。再复杂的分析也无法从不相关的数据中提取有意义的答案。
统计结论的可靠性也在很大程度上取决于样本量。考虑一个声称新的 250 美元跑鞋显著提高性能的说法。如果《纽约时报》的数据集包含 50 万次跑步时间,涵盖 50 种不同的鞋子,并且始终将这款鞋排名第一,证据就很有说服力。庞大的数据量本身就说明了问题。相反,如果只有少数跑者穿这款鞋跑得更快,很容易就是巧合。大样本为我们的发现提供了可信度,而小样本需要更谨慎的解释。
用伯努利分布建模二元结果
最简单但最基础的统计模型是 伯努利模型 (Bernoulli model),它描述只有两种可能结果的随机现象。伯努利随机变量只能取值 1("成功")或 0("失败")。例子随处可见:抛硬币(正面/反面)、考试结果(通过/不通过)或患者康复(治愈/未治愈)。
伯努利分布由单一参数 p 定义,即"成功"的概率。我们写作:
$P(\mathrm{结果}=1) = p$ 和 $P(\mathrm{结果}=0) = 1-p$。
当我们说随机变量 $X$ 服从参数为 $p$ 的伯努利分布时,我们写作 $X \sim \mathrm{Bernoulli}(p)$。
伯努利模型是统计学的基石。许多复杂模型都基于它构建。例如,如果我们想知道新药的真实治愈率(p),我们可以将每个患者的结果($R_i$)建模为伯努利变量:如果治愈则 $R_i=1$,否则为 0。在 100 人试验中治愈患者的总数是这些伯努利变量的和,服从二项分布 $Binomial(n=100, p)$。
将结果编码为 0/1 也简化了计算。伯努利变量的一个关键性质是其期望值(或均值)等于其成功概率:$E[R_i] = 1 \cdot p + 0 \cdot (1-p) = p$。
这意味着如果我们有 $n$ 个独立观察,样本均值 $\hat p = \frac{1}{n}\sum_{i=1}^n R_i$ 就是我们样本中成功的比例。这个样本比例是我们对真实概率 $p$ 的自然估计。
例子:接吻研究 一项有趣的研究观察接吻情侣是否倾向于将头偏向右侧或左侧。研究人员收集了 $n=124$ 对情侣的数据,向右偏记录为"1",向左偏记录为"0"。在这个数据集中,80 对情侣向右偏。
我们对向右偏情侣比例的估计是: $\hat p = 80/124 \approx 0.645$
这表明大约 64.5% 的情侣向右偏。这个数字大于 50%,但它是显著大于 50% 吗?这是真正的倾向还是我们样本中的随机巧合?伯努利模型为回答这个问题提供了框架,我们稍后会探讨。
i.i.d. 假设:统计学的基石
在构建模型时,首先要问的问题之一是数据是否可以被视为 i.i.d.(独立同分布,independent and identically distributed)。这个假设是许多经典统计定理的基础。
独立性 (Independence)
独立性意味着每个观察都与其他观察无关;一次试验的结果不会影响另一次试验的结果。
- 好例子: 连续投掷公平骰子,或随机拨号电话调查的回应。
- 坏例子: 每日股价(今天的价格与昨天的相关)、社交媒体上的"点赞"(朋友的行为会相互影响)或同一家庭成员的血压读数(共同的遗传和生活方式)。
当独立性被违反时,大数定律和中心极限定理等标准工具不能直接应用。需要更高级的模型(如时间序列、网络模型或混合效应模型)。
同分布 (Identically Distributed)
这意味着所有观察都是从相同的潜在概率分布生成的,具有相同的参数。
- 好例子: 重复投掷同一枚硬币,正面概率始终为 0.5。从大型全国人口中随机抽样进行政治民调。
- 坏例子: 在接吻研究中,如果在机场不同时间收集数据,人口统计(因此行为)可能会改变,违反假设。类似地,如果关于惯用手偏好的研究混合了左撇子和右撇子而没有考虑到这一点,数据就不是来自单一、相同的分布。
在实践中,如果我们识别出具有不同特征的不同子群体,我们应该使用更复杂的技术,如分层建模,而不是假设单一、均匀的分布。
i.i.d. 假设是一个强大的简化。良好的实验设计——使用随机化、盲法和仔细抽样——往往旨在创造数据可以合理地被视为 i.i.d. 的条件。
样本均值的性质
样本均值(或样本平均)是最基本的统计量。对于 i.i.d. 数据,它作为总体均值的自然估计器。对于我们的伯努利样本,样本均值是 $\hat p$。
期望(无偏性)
样本均值 $\hat p$ 的期望值是真实的总体比例 $p$。 $$E[\hat p] ;=; E!\Big[\frac{1}{n}\sum_{i=1}^n R_i\Big] ;=; \frac{1}{n}\sum_{i=1}^n E[R_i] ;=; \frac{1}{n}\cdot n p ;=; p.$$ 这个性质使 $\hat p$ 成为 $p$ 的无偏估计器。平均而言,我们的估计会命中真实值。
方差(精度)
当然,任何单次实验都不会完全匹配期望。样本均值的方差告诉我们它预期在真实值周围波动多少。对于方差为 $Var(R_i) = p(1-p)$ 的独立 $R_i$,$\hat p$ 的方差是: $$\operatorname{Var}(\hat p) ;=; \operatorname{Var}!\Big(\frac{1}{n}\sum_{i=1}^n R_i\Big) ;=; \frac{1}{n^2}\sum_{i=1}^n \operatorname{Var}(R_i) ;=; \frac{1}{n^2}\cdot n,p(1-p) ;=; \frac{p(1-p)}{n}.$$ 这个公式极其重要。它表明我们估计的方差随着样本量 $n$ 的增加而减少。这是大样本威力的数学基础:它们产生更稳定和精确的估计。
大数定律和中心极限定理
这些性质导致了统计学中两个最重要的定理:
- 大数定律 (Law of Large Numbers, LLN): 当样本量 $n$ 无限增大时,样本均值 $\hat p$ 收敛于真实总体均值 $p$。这保证了有足够的数据,我们的估计将任意接近真相。
- 中心极限定理 (Central Limit Theorem, CLT): 对于足够大的样本量 $n$,样本均值 $\hat p$ 的分布近似为正态分布,无论原始数据的分布如何。 $$\hat p \approx N!\Big(p,;\frac{p(1-p)}{n}\Big)$$ CLT 是一个强大的工具,因为正态分布已被充分理解,允许我们计算概率并为我们的估计构造置信区间。
例子:低温电子显微镜 (Cryo-EM)
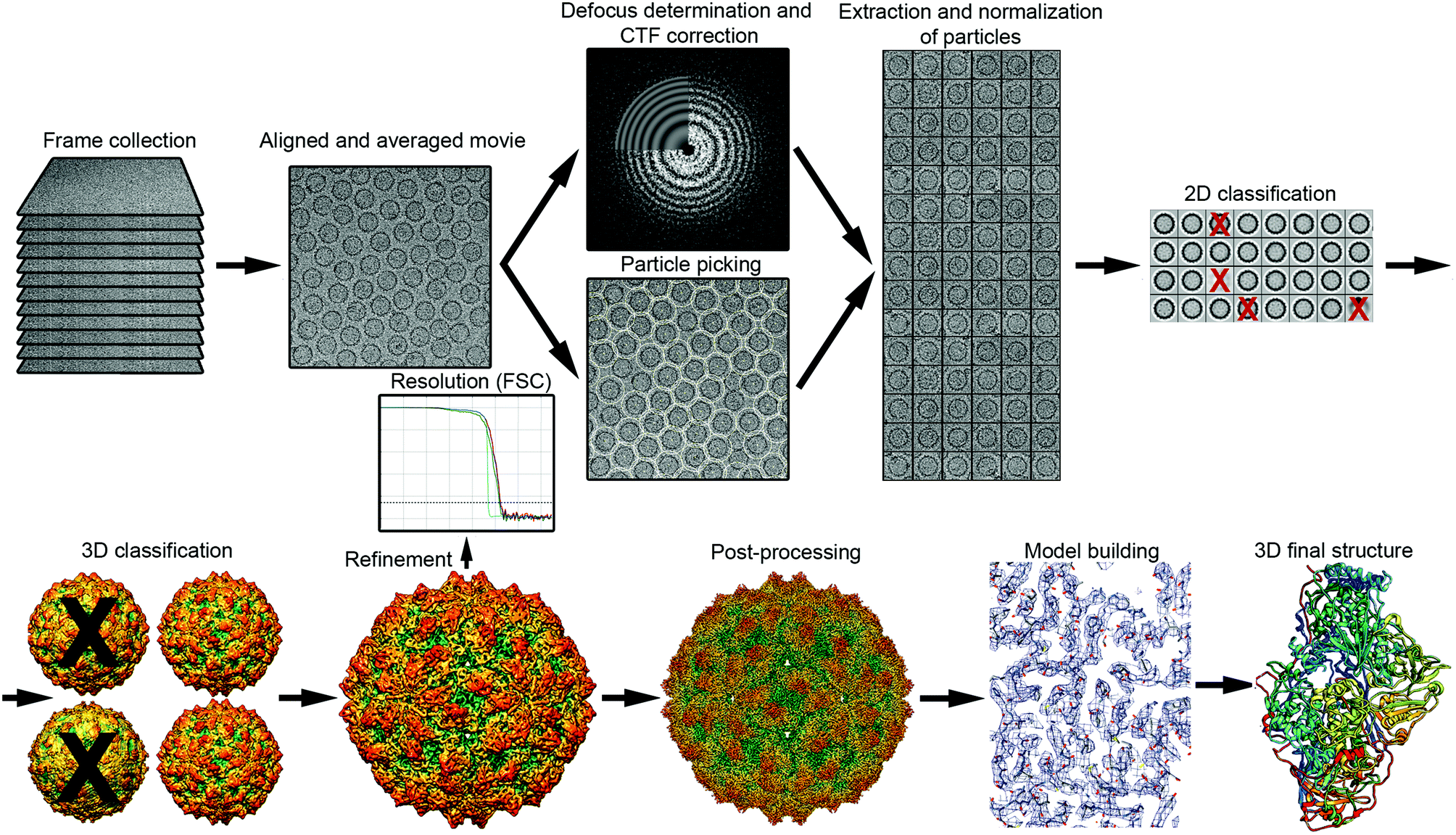
i.i.d. 数据平均的威力在低温电子显微镜中得到了完美的体现,这是一种确定生物分子 3D 结构的革命性技术。科学家冷冻并拍摄数十万个单独的蛋白质颗粒,但每个图像都非常嘈杂。

为了重构结构,图像被对齐然后平均。因为每个图像中的噪声是随机和独立的,它在平均过程中相互抵消。然而,蛋白质的微弱潜在信号是一致的,并在平均中得到强化。
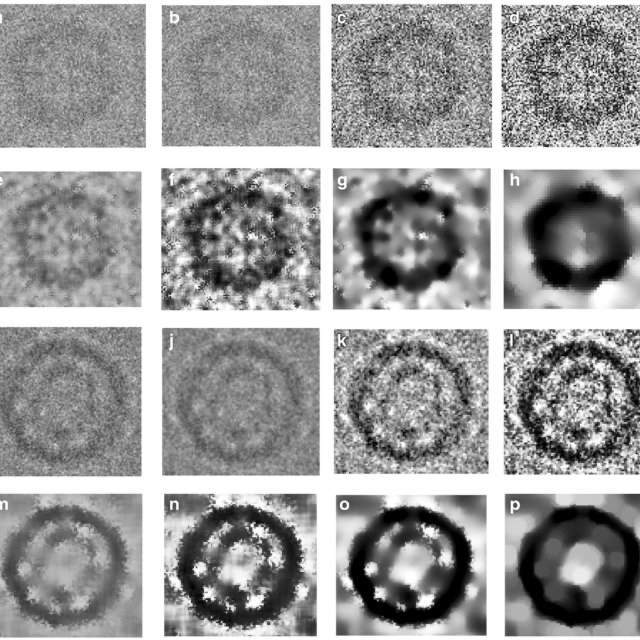
这是我们讨论的原理的直接应用:
- 独立性: 每个图像中的噪声是随机的,与其他图像无关。
- 同分布: 所有颗粒都是相同的蛋白质,所以潜在信号是相同的。
- 大数定律: 通过平均数万张图像,随机噪声平均为零。
- 方差缩减: 最终图像中噪声的方差减少了 $n$ 倍,使信噪比大大提高。
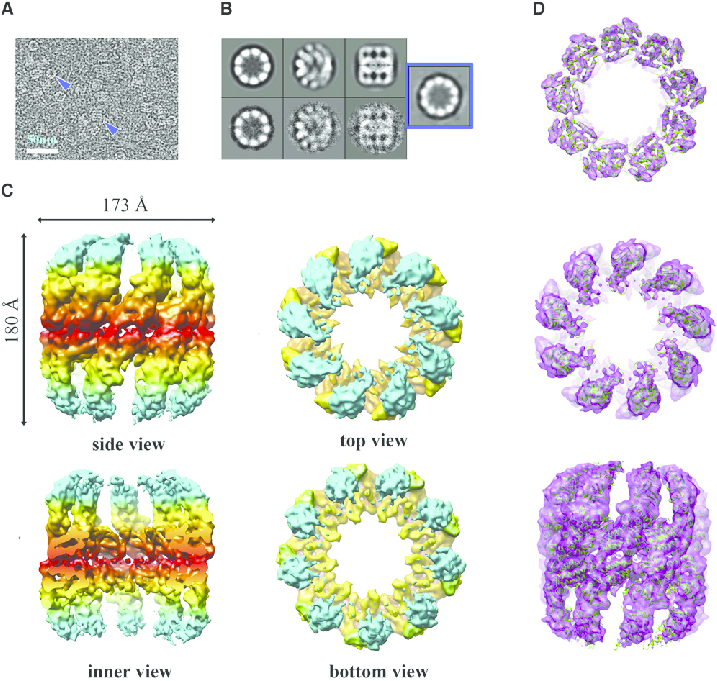
结果是分子的高分辨率 3D 图,这一成就因统计学平均的基本原理而成为可能。
理论与模拟:量化误差的两种方法
我们如何量化估计 $\hat p$ 中的不确定性?我们有两个主要工具:理论公式和计算模拟。
1. 解析方法(理论)
使用概率论,我们可以推导误差度量的精确公式。如我们所见,$\hat p$ 的标准差,称为标准误差,是 $\sigma_{\hat p} = \sqrt{p(1-p)/n}$。这给我们一个估计误差规模的直接度量。
我们可以使用这个,通常结合中心极限定理,来回答概率问题。例如,"我们的估计 $\hat p$ 与真实值 $p$ 相差超过 10% 的概率是多少?"这可以表示为 $P(|\hat p - p| > 0.1)$。对于大的 $n$,我们可以使用正态分布来近似这个。
这种解析方法很强大,因为它给我们关于不确定性的精确、定量答案。
2. 数值方法(模拟)
当理论公式过于复杂或难以处理时,我们可以使用蒙特卡罗模拟。想法是使用计算机在特定假设下(如假设真实 $p=0.5$)模拟我们的实验数千次。
对于接吻研究,我们可以模拟 100,000 次实验,每次有 124 对"情侣"。在每次实验中,我们生成 124 个随机 0/1 值($p=0.5$)并计算模拟的 $\hat p$。通过绘制这 100,000 个模拟 $\hat p$ 值的直方图,我们得到一个经验分布,显示如果真实比例为 50%,我们可以期望的结果范围。
如果我们实际观察的值($\hat p = 0.645$)落在这个直方图的很低密度区域(即在尾部),这表明我们的初始假设($p=0.5$)可能是错误的。
模拟是直观和灵活的,但它取决于我们正确建模数据生成过程的能力,并需要大量计算来精确估计非常小的概率。
假设检验与统计显著性
让我们回到接吻研究。我们观察到的比例是 $\hat p = 0.645$。这是否是强有力的证据来断定人们有向右偏的偏好?这是假设检验的问题。
框架如下:
陈述假设:
- 零假设 ($H_0$): 这是"无效应"或"无差异"的情景。这里,$H_0: p = 0.5$(向右或向左偏没有偏好)。
- 备择假设 ($H_1$): 这是我们想要证明的。这里,$H_1: p > 0.5$(偏向右的偏好)。
计算检验统计量和 p 值: 我们的检验统计量是"成功"(向右偏)的数量,即 $X=80$。p 值量化这个结果有多极端。它定义为假设零假设为真,观察到至少与我们数据一样极端结果的概率。
在这种情况下:$p\text{-值} = P(X \ge 80 \mid p=0.5)$。
如果这个 p 值非常小,意味着在"无偏好"假设下我们观察到的数据极不可能。这将导致我们拒绝零假设,支持备择假设。
为了建立直觉,我们可以运行模拟。我们假设零假设为真($p=0.5$)并多次模拟实验。
import numpy as np
import matplotlib.pyplot as plt
# ---------------- user-adjustable parameters ----------------
p_true = 0.5 # probability under H0 (no preference)
n_sample = 124 # couples per experiment
N_sim = 100_000 # how many experiments to simulate
obs_hatp = 0.645 # the real sample proportion we observed
# ------------------------------------------------------------
rng = np.random.default_rng(seed=2025)
data = rng.binomial(1, p_true, size=(N_sim, n_sample))
hat_p = data.mean(axis=1)
# empirical p-value: proportion of experiments where hat_p ≥ observed value
p_empirical = np.mean(hat_p >= obs_hatp)
# ---------- plot ----------
plt.figure(figsize=(6,4))
plt.hist(hat_p, bins=40, density=True, edgecolor="black", alpha=0.9, color="#F5A623")
plt.axvline(obs_hatp, ls="--", lw=2, color="#FF6F00", label=fr"$\hat p_{{obs}}={obs_hatp}$")
plt.title(fr"Monte-Carlo distribution of $\hat p$ ($n={n_sample},\,p={p_true}$)")
plt.xlabel(r"sample proportion $\hat p$")
plt.ylabel("density")
plt.legend()
plt.tight_layout()
plt.show()
print(f"Empirical P(hat_p ≥ {obs_hatp}) = {p_empirical:.5f}")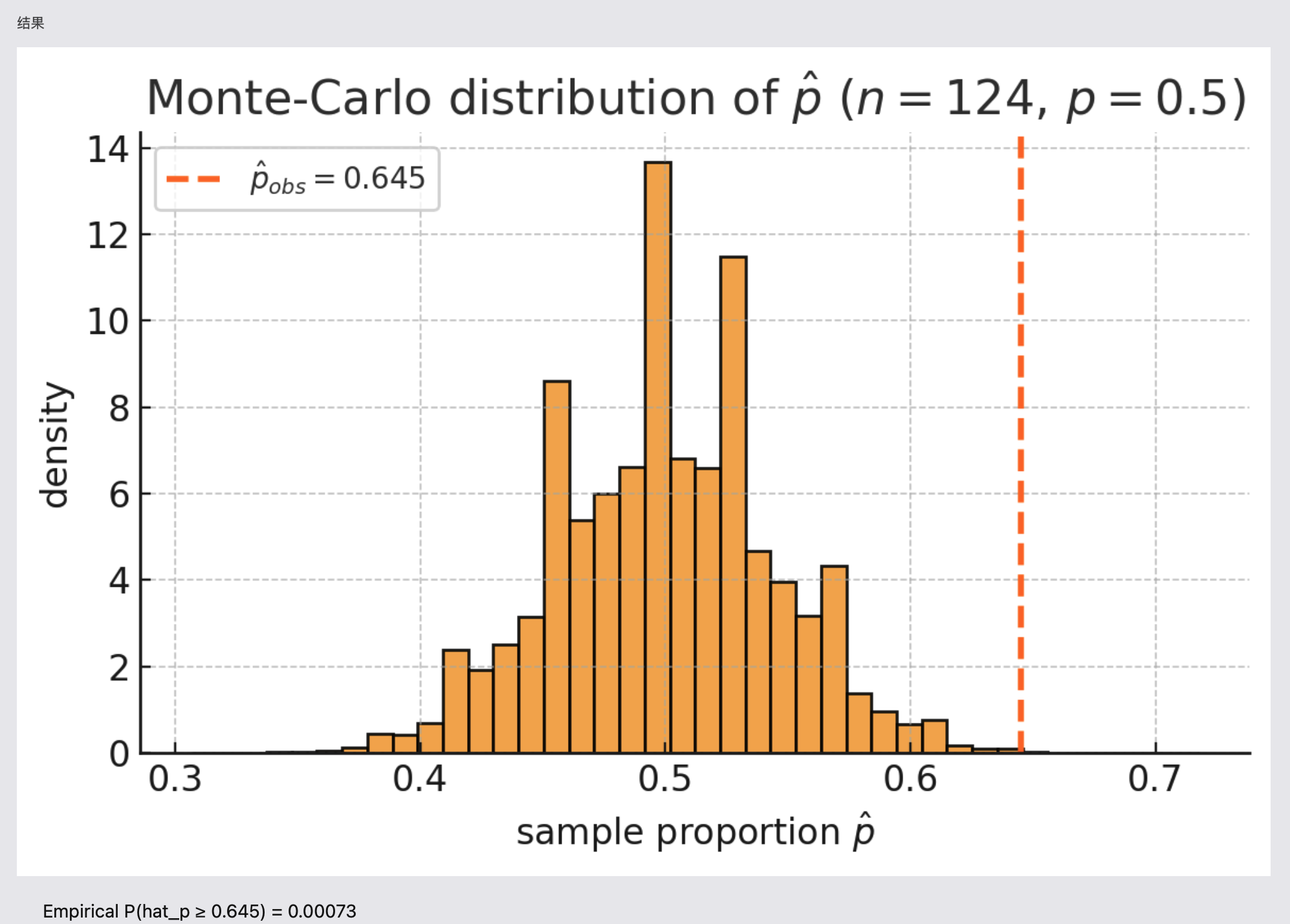
直方图显示了来自 100,000 次模拟实验的样本比例分布,其中真实偏好为 50/50。我们观察到的 0.645 值远在右尾。
模拟右尾概率
$\widehat{P}(\hat p\ge 0.645);=;0.00084;;(\text{约 }0.084%)$
这个模拟 p 值极小。它告诉我们,如果真的没有偏好,我们看到这种偏向右侧的结果的概率不到千分之一。因此,我们有强有力的统计证据拒绝零假设,并得出结论:接吻时向右偏确实存在真实偏好。
假设检验的替代方法是构造置信区间。$p$ 的 95% 置信区间可能是,例如,[0.56, 0.72]。这给我们 $p$ 真实值的合理范围。由于这个区间不包含 0.5,它导致与我们假设检验相同的结论:真实比例很可能大于 50%。
收集好数据的原则
任何统计结论的质量都基本上受限于数据的质量。**"垃圾进,垃圾出"**的原则至关重要。以下是收集可靠数据的关键考虑因素。
对照实验 vs. 观察性研究: 尽可能选择对照实验。通过随机分配受试者到治疗组(如接受新药)和对照组(如接受安慰剂),我们可以隔离治疗效果并最小化混杂偏差。随机化是确保 i.i.d. 假设成立的强大工具。
代表性抽样: 对于观察性研究,目标是获得一个作为总体微型复制品的样本。简单随机抽样是理想的,但分层抽样等策略可能更有效。关键是避免选择偏差。仅通过在线论坛进行的调查可能过度代表特定人群,无法推广到整个人口。
样本量规划: 在开始研究之前,明智的做法是进行效应分析来估计所需的样本量。这确保研究足够大以检测有意义的效应,而不会在收集过多数据上浪费资源。
避免依赖性: 数据收集过程本身不应引入依赖性。调查受访者不应讨论答案,实验对象应彼此隔离。如果依赖性不可避免(如时间序列数据),必须用适当的模型来解释它们。
伦理和实际约束: 现实世界的数据收集常常受到伦理和后勤的约束。给危重患者安慰剂可能是不道德的;完美的随机样本可能太昂贵。在这些情况下,我们必须在约束内找到最佳设计,并在报告结果时对数据限制保持透明。
结论
统计学不仅仅是公式的集合;它是一种关于不确定性和从世界中学习的原则性思维方式。从框定问题和设计实验到建立模型和量化不确定性,每一步都至关重要。通过理解核心假设(如 i.i.d.)和估计器的基本性质,我们可以建立对结论的信心。
从简单伯努利试验到复杂现实问题(如 Cryo-EM 重构)的旅程都建立在这些基本思想之上。当我们继续探索更高级的模型时,我们必须始终回到这些第一原理:理解你的数据来源,明确你的假设,并诚实面对结论的局限性。精心设计的数据收集,配合合理的分析,是将信息转化为洞察的关键。